Next week is the biggest event for the SQL Server community: PASS Summit 2017! I will be presenting the Real-world SQL Server R Services session with two of our customers – APT and Financial Fabric. I will also be part of the SQL Clinic, so I’m really excited and pumped about next week!
Being a Data Nut, it suddenly occurred to me today: what if we can import all the PASS Summit 2017 session titles, abstracts and other details into a SQL Server table? And once this thought was in my mind, there was no stopping me! The wonderful thing is that with Python in SQL Server 2017 you can leverage rich libraries such as Beautiful Soup 4, URLLib3 to parse HTML and then present it as a structured table (using Pandas) which SQL can then consume.
The code below will do exactly that for you. It leverages the above mentioned Python libraries, so prior to executing the script you must install two libraries (bs4 & urllib3) using PIP. (Note that pip.exe is present under the C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES\scripts folder; change drive letters as appropriate for your installation.) Also note that PIP must be executed from within an administrative CMD prompt in Windows.
The other step for the below script to run correctly is that outgoing Internet access must be allowed for the SQL instance’s R / Python scripts. By default, we block such access. To edit the rule temporarily (we strongly recommend to not disable this rule on a permanent basis) use wf.msc to open the Firewall with Advanced Security console, and then locate the rule “Block network access for R local user accounts in SQL Server instance ” in the Outbound Rules section. Right click and Disable the rule for now; and DO NOT FORGET to enable it later on!
Alright, here is the code!
CREATE DATABASE PASS2017
GO
USE PASS2017
GO
DROP TABLE IF EXISTS PASS2017Sessions
CREATE TABLE PASS2017Sessions
(Abstract nvarchar(max)
, SessionLevel int
, Speaker1 nvarchar(100)
, Speaker2 nvarchar(100)
, Speaker3 nvarchar(100)
, Title nvarchar(4000)
, Track nvarchar(50)
, SessionId int
);
GO
INSERT PASS2017Sessions
exec sp_execute_external_script @language = N'Python',
@script = N'
from bs4 import BeautifulSoup
import urllib3
import re
import pandas as pd
http = urllib3.PoolManager()
schedpage = http.request("GET", "http://www.pass.org/summit/2017/Sessions/Schedule.aspx")
schedpage.status
soup_schedpage = BeautifulSoup(schedpage.data, "lxml")
schedpage.close()
documents = []
processedsessions = []
sessioncells = soup_schedpage.find_all("div", class_ = "session-schedule-cell", recursive=True)
for currsess in sessioncells:
hrefs = currsess.find_all("a")
if (len(hrefs) >= 1):
rowdict = {}
# session title
rowdict["Title"] = hrefs[0].text
# session level
sesslevel = currsess.find("p", id = re.compile("plcLevel"))
if (sesslevel != None):
rowdict["Level"] = sesslevel.text.replace("Level: ", "")
else:
rowdict["Level"] = None
# session track
allps = currsess.find_all("p")
rowdict["Track"] = allps[len(allps) -2].text
# get into session page itself
if ("href" in hrefs[0].attrs):
sessurl = hrefs[0].attrs["href"]
# session ID
mtch = re.search(r"sid=(d+)", sessurl)
if (mtch is None):
continue
# check if this session ID was already processed
sessionid = mtch.group(1)
if (sessionid in processedsessions):
continue
processedsessions.append(sessionid)
rowdict["sessionid"] = sessionid
sesspage = http.request("GET", sessurl)
soup_sesspage = BeautifulSoup(sesspage.data, "lxml")
sesspage.close()
# session abstract
sessabstract = soup_sesspage.find("pre", class_ ="abstract")
rowdict["Abstract"] = sessabstract.text
if (len(rowdict["Abstract"]) == 0):
continue
# speakers
allspeakers = soup_sesspage.find_all("a", id=re.compile("Detail.+lnkSpeaker"))
rowdict["Speaker1"] = None
rowdict["Speaker2"] = None
rowdict["Speaker3"] = None
if (len(allspeakers) >= 1):
rowdict["Speaker1"] = allspeakers[0].text
if (len(allspeakers) >= 2):
rowdict["Speaker2"] = allspeakers[1].text
if (len(allspeakers) == 3):
rowdict["Speaker3"] = allspeakers[2].text
else:
continue
documents.append(rowdict)
OutputDataSet = pd.DataFrame(documents)'
GO
select *
from PASS2017Sessions
GO
If all goes well you should see the results:
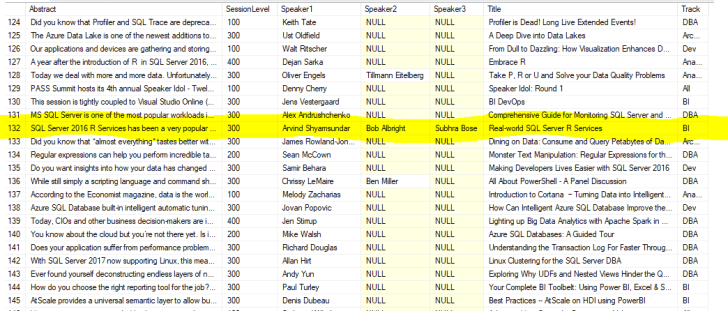
Isn’t that so cool! Play around with it and let me know what you think. And if you are at the Summit and interested in SQL Server ML Services, a friendly reminder to come to the Real-world SQL Server R Services session. See you later!
Disclaimer
This Sample Code is provided for the purpose of illustration only and is not intended to be used in a production environment. THIS SAMPLE CODE AND ANY RELATED INFORMATION ARE PROVIDED “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND/OR FITNESS FOR A PARTICULAR PURPOSE. We grant You a nonexclusive, royalty-free right to use and modify the Sample Code and to reproduce and distribute the object code form of the Sample Code, provided that You agree: (i) to not use Our name, logo, or trademarks to market Your software product in which the Sample Code is embedded; (ii) to include a valid copyright notice on Your software product in which the Sample Code is embedded; and (iii) to indemnify, hold harmless, and defend Us and Our suppliers from and against any claims or lawsuits, including attorneys’ fees, that arise or result from the use or distribution of the Sample Code. This posting is provided “AS IS” with no warranties, and confers no rights.


