This week I happened to assist with an internal application where there was a performance issue with a specific query. One of my observations with that query was that it was doing self-joins in order to determine the latest iteration of a specific record. That’s a common anti-pattern which can be fixed by using T-SQL’s windowing functions, such as ROW_NUMBER() or RANK().
The Inefficient Way
To give more context, here is an example from the Contoso Retail DW database. The requirement (very similar to the actual customer case) here is to obtain a list of all the customers who have placed an order with us, and for each of those customers, obtain the date of the latest order. The implementation that I first noticed was using a self-join as given below; notice the special case handling where the customer has 2 orders on the same day and then the order number (the OnlineSalesKey column here) becomes the tie-breaker:
SELECT l.CustomerKey ,l.DateKey AS LatestOrder FROM dbo.FactOnlineSales l LEFT JOIN dbo.FactOnlineSales r ON l.CustomerKey = r.CustomerKey AND ( l.DateKey < r.DateKey OR ( l.DateKey = r.DateKey AND l.OnlineSalesKey > r.OnlineSalesKey ) ) WHERE r.DateKey IS NULL
This query is *extremely* inefficient, burning 100% CPU on my i7 laptop with 8 logical CPUs! On my laptop it will run for well over 10 minutes before I get impatient and cancel. For reference, here is the estimated execution plan for the above query (scroll to the right and note the query cost of 167692).

Just for kicks, I ran the above query with MAXDOP 144 (NOT a good idea, but this was for fun) on our lab machine which has 144 logical CPUs and here is the picture I see there 🙂 Obviously NOT something you want in production!

Rewriting the query
Now, the efficient way to re-write this is to use Ranking Functions in T-SQL. These have been around a while (SQL 2005 actually!) but I feel they are under-utilized. Here is the query re-written using the ROW_NUMBER() function. This solution also elegantly takes care of the above tie-breaking logic which required the disjunction (OR predicate) in the previous query.
WITH NumberedOrders AS ( SELECT CustomerKey ,Datekey ,ROW_NUMBER() OVER ( PARTITION BY CustomerKey ORDER BY Datekey DESC ,OnlineSalesKey DESC ) AS RowNumber FROM FactOnlineSales ) SELECT CustomerKey ,Datekey FROM NumberedOrders WHERE RowNumber = 1
Here is the new execution plan. Note that the cost is also much lesser: 447.

Here are the execution statistics of this query, it completes in 43 seconds compared the self-join approach taking forever!
- Table ‘FactOnlineSales’. Scan count 9, logical reads 92516, physical reads 0, read-ahead reads 72663, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 31263, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 19231 ms, elapsed time = 43834 ms.
Moral of the story: next time you see query patterns involving self joins to achieve this kind of ‘latest record of a particular type’ take a pause and see if T-SQL Ranking Functions can help!

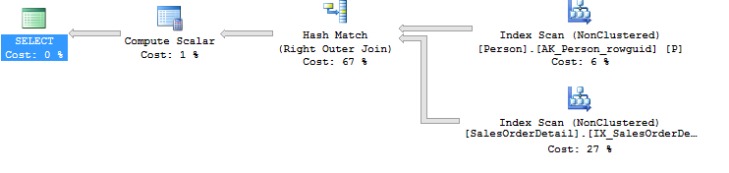 These two queries are functionally equivalent (because in this case there is a unique key on the BusinessEntityId column) and return the same set of results. As you can see the Person table is just accessed once in the revised query. The cost of the re-written query is also ~ 6 times lesser than the original query! This kind of optimization is referred to as
These two queries are functionally equivalent (because in this case there is a unique key on the BusinessEntityId column) and return the same set of results. As you can see the Person table is just accessed once in the revised query. The cost of the re-written query is also ~ 6 times lesser than the original query! This kind of optimization is referred to as 