Happy New Year 2014 to all of you! With SQL Server 2014 set to release this year, I’m sure you are all excited about the months to come.
In my previous post I had reviewed the classic ways of obtaining ‘normalized’ text for ad-hoc SQL queries. Do take a minute to glance at that post in case you have not already done so. Both the methods described previously are dynamic – they need an active workload to operate upon. So if you have a static set of queries captured somewhere – such as a .SQL file or such, then we need an alternate method.
Algorithm
If you think about it, the core of normalizing these ad-hoc query text patterns is to identify literals and replace then with a generic / common value. Once the specific literal values are replaced with their generic ‘placeholders’ then it becomes a relatively easy task to identify commonalities.
To identify commonalities we propose to use a hashing algorithm, conceptually similar to the one used in the previous approaches. However, when computing hashes, there is another problem to consider: minor differences in whitespace / alphabet case of the query text will cause different hash values to be raised for essentially identical text.
ScriptDom Implementation
The first thing to consider is what kind of literals we would replace. In the ScriptDom class hierarchy, we have the following derived classes for the parent Literal class:
- IntegerLiteral: whole numbers
- NumericLiteral: decimal numbers such as 0.03
- RealLiteral: numbers written with scientific notation such as 1E-02
- MoneyLiteral: values prefixed with currency symbol such as $12
- BinaryLiteral: such as 0xABCD1234
- StringLiteral: such as ‘Hello World’
- NullLiteral: the NULL value
- DefaultLiteral: the DEFAULT keyword
- MaxLiteral: the MAX specifier
- OdbcLiteral: ODBC formatted literal such as { T ‘blah’ }
- IdentifierLiteral: ‘special’ case when an identifier is used as a literal. I’ve never seen a real world example of this

We need to keep this in mind when we write the visitor to traverse through the AST.
Visitor definition
Next, we need to setup our visitor. We will use the Visitor pattern to do this, and implement overridden methods to handle the various types of literals described above. And for each type of literal we will replace the value of the literal with a fixed, generic value. Here is an example for the real literal visitor method:
public override void ExplicitVisit(RealLiteral node)
{
node.Value = “0.5E-2”;
base.ExplicitVisit(node);
}
Visitor invocation
For performance reasons we will call the visitor with the Parallel.ForEach loop which makes efficient use of multi-core CPUs:
Parallel.ForEach(
(frag as TSqlScript).Batches,
batch =>
{
myvisitor visit = new myvisitor();
batch.Accept(visit);
This way, each T-SQL batch in the original script is visited on a separate thread.
Regenerate the Script
Once the visitor does its job to ‘normalize’ the various literals encountered, the next step is to generate the script based on the tokens already obtained. That will take care of one of the 2 problems we spoke about – namely whitespace. We can do that using one of the many SqlScriptGenerator classes available (there is one for each compatibility level.) In the code snippet below, srcgen is one of the SqlScriptGenerator classes and script holds the output:
scrgen.GenerateScript(batch, out script);
Calculate the hash
Once the normalized script is re-generated from the SqlScriptGenerator class, it can then be run through a proper hash algorithm (in this sample we use SHA1) to calculate the hash value of the given script. Here is where we also handle the case sensitive / insensitive nature of the script:
- For case insensitive cases, we simply convert the generated script to lower case before we compute the hash.
- For case sensitive, we calculate the hash as-is on the generated script.
using (var hashProvider = new SHA1CryptoServiceProvider())
{
if (caseSensitive)
{
hashValue = Convert.ToBase64String(hashProvider.ComputeHash(Encoding.Unicode.GetBytes(script)));
}
else
{
hashValue = Convert.ToBase64String(hashProvider.ComputeHash(Encoding.Unicode.GetBytes(script.ToLowerInvariant())));
}
}
Track unique hashes
We can use a simple Dictionary class in .NET to track these, along with usage counts for each bucket. Each bucket also tracks an example of the batch (the original text itself.)
Sample output
The sample project when compiled and executed as below gives us the following output.
Command line
TSQLTextNormalizer.exe c:tempinput.sql c:tempoutput.sql 110 false
Input
select * from ABC
where
i = 1
GO
select * from abC where i = 3
GO
Output
— 2 times:
select * from ABC
where
i = 1
GO
That’s it! You can use this in many cases, limited only by your imagination And more importantly I hope it showed you the power and flexibility of the ScriptDom classes.
[EDIT 2022-07-27] The sample code for this post is now on GitHub. Please upvote the repo on GitHub if you liked this post and found the sample code useful. The URL is https://github.com/arvindshmicrosoft/SQLScriptDomSamples/tree/main/8_TSQLTextNormalizer
Disclaimer
This Sample Code is provided for the purpose of illustration only and is not intended to be used in a production environment. THIS SAMPLE CODE AND ANY RELATED INFORMATION ARE PROVIDED “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND/OR FITNESS FOR A PARTICULAR PURPOSE. We grant You a nonexclusive, royalty-free right to use and modify the Sample Code and to reproduce and distribute the object code form of the Sample Code, provided that You agree: (i) to not use Our name, logo, or trademarks to market Your software product in which the Sample Code is embedded; (ii) to include a valid copyright notice on Your software product in which the Sample Code is embedded; and (iii) to indemnify, hold harmless, and defend Us and Our suppliers from and against any claims or lawsuits, including attorneys’ fees, that arise or result from the use or distribution of the Sample Code.
This posting is provided “AS IS” with no warranties, and confers no rights. Use of included script samples are subject to the terms specified at http://www.microsoft.com/info/cpyright.htm.




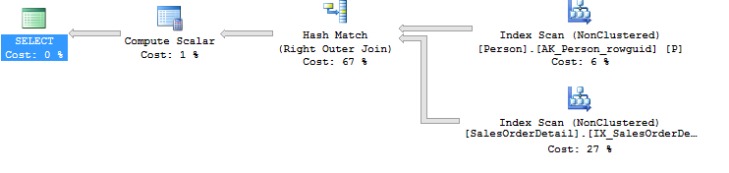 These two queries are functionally equivalent (because in this case there is a unique key on the BusinessEntityId column) and return the same set of results. As you can see the Person table is just accessed once in the revised query. The cost of the re-written query is also ~ 6 times lesser than the original query! This kind of optimization is referred to as
These two queries are functionally equivalent (because in this case there is a unique key on the BusinessEntityId column) and return the same set of results. As you can see the Person table is just accessed once in the revised query. The cost of the re-written query is also ~ 6 times lesser than the original query! This kind of optimization is referred to as 

