Hi there! If you have been working with SQL Server for any length of time, I am sure you know how crucial I/O is to the overall reliability of your SQL Server instance. Many years ago (over a decade now, actually!) we released SQLIOSim, which has been included in the out-of-box installations for SQL Server for many releases now. You can find this utility in the same folder that SQLServr.exe is (typically something like C:\Program Files\Microsoft SQL Server\MSSQL14.SQL2017\MSSQL\Binn).
This post is not about how to run SQLIOSim and what is the right usage for the tool (for example, it is not appropriate to use this for performance benchmarking, rather it is a pass / fail type verification of how reliable your storage is under load.) This post is about a very specific (and very rare) error which I recently hit on a server. In that case, SQLIOSim was running and the server had to be hard-rebooted due to I/O stack problems (the RAID controller in that server was faulty.) After reboot and fixing the issue with the RAID controller, I tried to restart SQLIOSim, but it would fail to run and complain with an error as below:
Error: 0x8009000F Error Text: Object already exists. Description: Failed to create random hash
This was not an error which I’d seen earlier so I had to debug it a bit. After some searching I found some very interesting facts:
- SQLIOSim uses Microsoft CryptoAPI to generate random values for the synthetic test data that it uses
- CryptoAPI in turn uses something called a ‘key container’ which the cryptographic provider in turn uses to perform the actual work of generating random numbers
Now, one user account in Windows can have multiple ‘key containers’. SQLIOSim uses the so-called ‘default key container’ for the user account which is running the SQLIOSim utility. So the theory I started forming was that somehow I had lost access to the default key container for my user account.
Before you proceed, I must warn you that the steps below are potentially dangerous if executed wrongly. Here are two regulatory disclaimers I must present, and by reading further you agree to these disclaimers and absolve me of any liability. If you need help and have questions on the steps below, please consider contacting Microsoft Support for professional assistance.
Disclaimers Please note that the third-party links are provided as-is and Microsoft does not offer any guarantees or warranties regarding the content on the third party site. Using tools like KeyPal, and / or editing NTFS permissions on System folders / files incorrectly can cause serious problems that may require you to reinstall your operating system. Use the tools at your own risk. This Information is provided for the purpose of illustration only and is not intended to be used in a production environment. THIS INFORMATION IS PROVIDED “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND/OR FITNESS FOR A PARTICULAR PURPOSE.
Disclaimer noted, now to investigate the issue further, I first used the KeyPal utility which can be quite useful for low-level CryptoAPI investigations, and located the default container for my account. The default key container is identified by the name of the user account, which in this case happens to be ‘myuser’. KeyPal prints out the details about the ‘unique container’ name (the GUIDs below) which correspond to a file which actually stores the key pairs for the default container. You can read more about the gory details at this page and here.
Keycontainer 50 : myuser Uniquecontainer: 4f274a21613b2c41c894534e8d09a8cd_0e489cc1-3b9a-49dc-b00b-6c6697e27995
FYI, the number ‘50’ mentioned above is the ordinal of the key container. Now that I located the Uniquecontainer name for the default key container for my user account, I used Windows Explorer to locate that file in the OS disk. In my case for example it was found (full path below) at:
c:\users\myuser\AppData\Roaming\MicrosoftCryptoRSAS-1-5-21-<somenumbers>-<somenumbers>-<somenumbers>-<somenumbers>\4f274a21613b2c41c894534e8d09a8cd_0e489cc1-3b9a-49dc-b00b-6c6697e27995
When I looked at the NTFS permissions for this file in Windows Explorer, it showed no entry for myuser. I then edited the NTFS permissions to grant Full Control to ‘myuser’. Once I did that, SQLIOSim executed correctly as it could then access the key container and then perform the necessary cryptographic random number generation for the test!





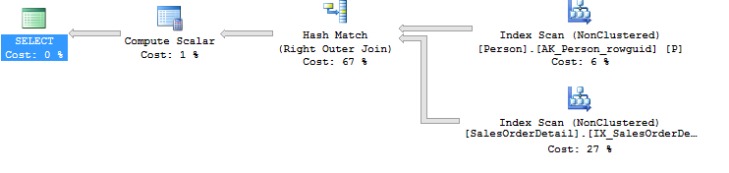 These two queries are functionally equivalent (because in this case there is a unique key on the BusinessEntityId column) and return the same set of results. As you can see the Person table is just accessed once in the revised query. The cost of the re-written query is also ~ 6 times lesser than the original query! This kind of optimization is referred to as
These two queries are functionally equivalent (because in this case there is a unique key on the BusinessEntityId column) and return the same set of results. As you can see the Person table is just accessed once in the revised query. The cost of the re-written query is also ~ 6 times lesser than the original query! This kind of optimization is referred to as 








![clip_image002[5]](https://msdnshared.blob.core.windows.net/media/MSDNBlogsFS/prod.evol.blogs.msdn.com/CommunityServer.Blogs.Components.WeblogFiles/00/00/00/64/64/metablogapi/7610.clip_image0025_424D2B71.jpg "clip_image002[5]")


![clip_image002[7]](https://msdnshared.blob.core.windows.net/media/MSDNBlogsFS/prod.evol.blogs.msdn.com/CommunityServer.Blogs.Components.WeblogFiles/00/00/00/64/64/metablogapi/2063.clip_image0027_5572B7D8.jpg "clip_image002[7]")
![clip_image004[5]](https://msdnshared.blob.core.windows.net/media/MSDNBlogsFS/prod.evol.blogs.msdn.com/CommunityServer.Blogs.Components.WeblogFiles/00/00/00/64/64/metablogapi/3542.clip_image0045_0F841569.jpg "clip_image004[5]")
